Memory-sharing: von grundlegend bis vollständig, mit Hazelcast IMDG
Memory-Sharing-Systeme können recht anspruchsvoll sein. Zum Beispiel müssen die Anwendungen die Daten überall gemeinsam nutzen/zugänglich/optimiert sein, und das in Echtzeit. Das kann bei einer Messaging-Anwendung genauso passieren wie bei Zeiterfassungssystemen für Mitarbeiter oder komplexen ERP-Systemen.
Die Entwicklung einer eigenen, dedizierten Lösung ist möglich, aber ein einfacherer Weg wäre die Verwendung/Integration einer Out-of-the-Box-Plattform. Ja, sie decken nicht immer alle Ihre Bedürfnisse ab, aber sie können umfassend genug sein, um einen guten Ausgangspunkt zu bilden, der nur geringfügige Anpassungen und/oder Erweiterungen benötigt.
Dies stimmt sich mit unseren Erfahrungen beim Aufbau von Hazelcast IMDG: Wir begannen mit einer relativ kleinen Anwendung, entdeckten dann neue Werkzeuge / Funktionen und hatten schließlich ein komplettes Ökosystem.
1. Unser spezieller Fall, unsere Bedürfnisse und unsere Optionen führten uns zu Hazelcast
In unserem speziellen Fall handelt es sich um eine Client-Server-App, mit Echtzeit-Datenflüssen vom Client zum Server. Wir müssen Teile der Daten von mehreren Maschinen über verschiedene Netzwerke zusammenführen. Es gibt keine hohe Nutzlast, aber wir brauchen eine absolut stabile und stetige Verbindung. In diesem Fall hilft es nicht, einen Push/Pull-Mechanismus für die Datenkommunikation zu verwenden, also brauchen wir einen gemeinsamen Datenbereich, in dem die Daten abgelegt werden sollen.
Der erste Ansatz war, ein Client-Server-Kommunikationstool zu entwickeln, das Kommunikation, Merge, Brain Split usw. beinhaltet. Aber im Jahr 2020+ haben wir die Möglichkeit, auf bestehende „Paketlösungen“ zurückzugreifen, die wir an unsere Bedürfnisse anpassen können. Anstatt das System also selbst zu entwickeln/implementieren, haben wir eine kurze Liste mit bestehenden Plattformen erstellt: Hazelcast, Redis, RabbitMQ, Apache Kafka.
Wir haben uns für Hazelcast entschieden, und zwar aus mehreren Gründen:
Erstens hat es einen kleinen Footprint: Es braucht nicht viel Speicherplatz, es sind nicht mehrere Server nötig – wir haben es einfach in unsere Anwendung eingebettet.
Dann hat es alle unsere Grundbedürfnisse erfüllt:
- In-Memory-Datenbank,
- Second-Level-Cache,
- persistierende Datenbank,
- Warteschlangen-Implementierung,
- großes Verbindungsmanagement.
Obwohl wir mit kleinen Teilen angefangen haben, haben wir immer mehr hinzugefügt: maps, shared objects, und topics. Hier ist, was wir von / mit Hazelcast verwendet haben:
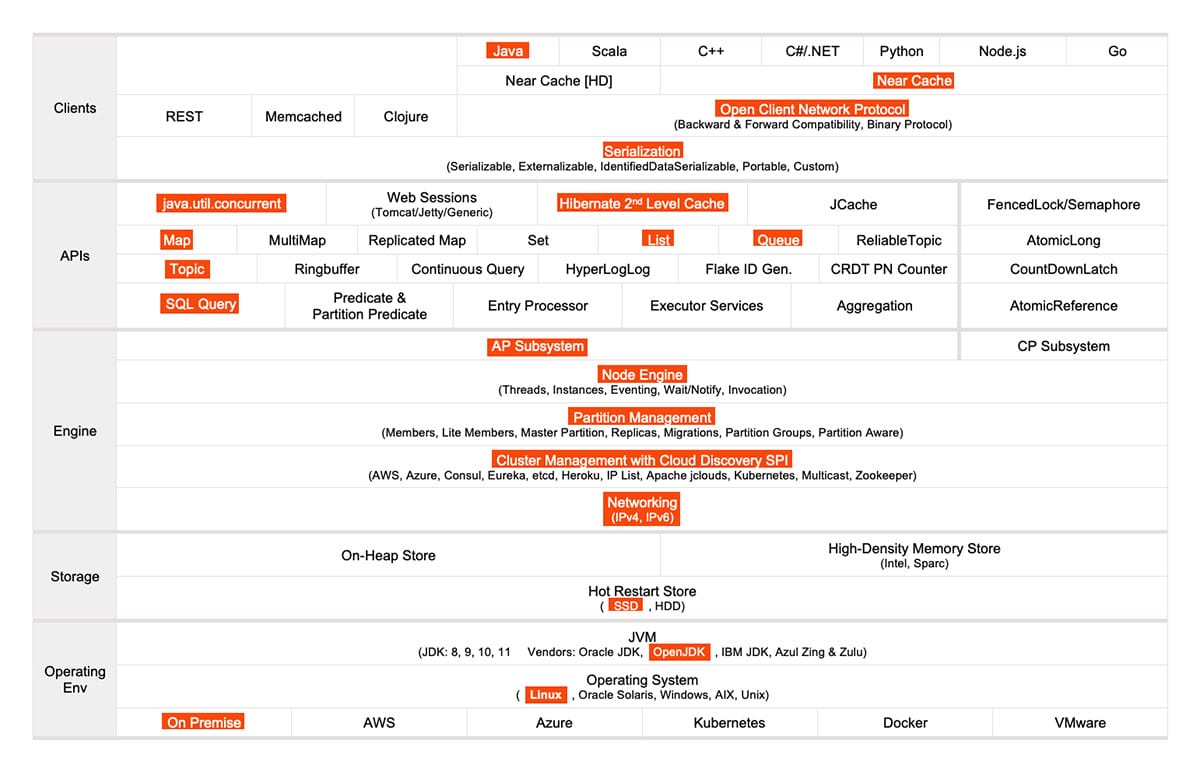
2. Wie wir Hazelcast benutzen
2.1. Ruf mich an, um mich zu erinnern
Hazelcast wurde zuerst vom Server, dann von jedem Client hochgefahren, wodurch ein Cluster entstand.
In der ersten Phase haben wir eine All-in-One-Warteschlange implementiert, bei der die Objekte von den Clients zum Master fließen. Zu diesem Zeitpunkt haben wir nur Nachrichten zwischen den Anwendungen ausgetauscht.
Ein HTTP-Anruf würde vom Client zum Server gesendet werden, um drei Dinge zu erreichen:
- „wir sind da“ kommunizieren,
- den Namen des Hazelcast-Clusters abrufen,
- und stellen die Verbindung her.
Aber dann treffen wir auf einige nicht-standardisierte Situationen:
- ungewöhnliche Kundenarchitekturen, bei denen Http-Anrufe abgelehnt werden,
- der Client und der Server befanden sich in verschiedenen Netzwerken.
Verbindungsmanagement ist nicht nur ein Hintergedanke. Die Verbindung von Anwendungen (z. B. über geografische Grenzen hinweg) erfordert oft einen erheblichen Zeit- und Entwicklungsaufwand. Gerade bei sensiblen, firewalled Anwendungen ist es für die Kundenfirma recht kompliziert, Kommunikationsports zu öffnen. Sehr kleine Details können große (und negative) Folgen haben. Mit Hazelcast haben wir einen vorgefertigten Algorithmus, der entweder die passenden Verbindungen findet oder die angegebenen Ports verwendet. Aufgrund seiner Entdeckungsstrategien können wir ihm einfach sagen: „Geh und finde Clients im Netzwerk, dann verbinde dich“.
Wir wollten also sehen, ob Hazelcast unsere nicht standardisierten Fälle lösen kann – und es hat sie gelöst. Unabhängig davon, ob wir uns im selben Netzwerk befinden oder Proxies verwenden, ist Hazelcast in der Lage, alle Knoten zu verbinden und einen Kommunikationskanal aufzubauen. Dies löste eine Menge Infrastrukturprobleme, so dass wir Hazelcast zum Standard machten, um alle anderen Kommunikationsmechanismen zu ersetzen. Hazelcast hat sich zu einem essentiellen Teil des Ökosystems entwickelt, und zwar in einem solchen Ausmaß, dass die Client-App gar nicht erst startet, wenn sie sich nicht mit dem Server verbinden kann.
2.2. …Aber ruf mich nicht zu oft an
Die nächste Speed-Bump, die mit der Latenz zusammenhängt, trat auf, als wir anfingen, große Datenmengen in die verteilte Warteschlange zu verschieben, die als Kommunikationskanal zwischen dem Server („Consumer“) und den Clients („Producer“) verwendet wird. Ein Objekt nach dem anderen in eine Warteschlange zu stellen und sie dann auf Serverebene zusammenzufassen, führte zu einer zusätzlichen Latenz (die proportional zur Datenmenge war).
Da die Reihenfolge der Objekte, die von verschiedenen Servern kommen, nicht so wichtig war, bestand unsere Lösung darin, die Objekte in Container zu packen und dann die Container mit Hazelcast zu verwenden. Anstatt dass wir Tausende von einzelnen Nachrichten lesen und pausieren, um zu prüfen, ob jede von ihnen aktuell ist, packt und platziert der Client sie nun in Hazelcast. Das Ergebnis: eine dramatisch verbesserte Leistung.
2.3. Wollen Sie mehr?
Die Lösung der Warteschlangen-Latenz gab uns die Zuversicht, dass Hazelcast auf weitere Bereiche erweitert werden kann. Also untersuchten wir, wie verschiedene Informationen (z. B. Konfigurationen) auf alle Knoten verteilt werden können. Wir begannen mit der Verwendung von Maps, die vom Server initialisiert und an die Clients verteilt werden.
Aber die Verwaltung der Maps an zwei verschiedenen Orten (sowohl in Hazelcast als auch in der Datenbank) kann kompliziert werden. Es gibt Momente, in denen alle Anwendungen geschlossen sind, wobei alle Informationen in der Datenbank gespeichert sind; beim Neustart müssen dann alle Informationen aus der Datenbank zurück in den Speicher bewegt werden.
Deshalb haben wir auf persistierte Maps umgestellt und lassen Hazelcast die Daten in der Datenbank persistieren, d.h. Hazelcast speichert, wann immer es optimal ist.
2.4. …Und mehr?
Als selbst die Maps nicht mehr ausreichten, gingen wir zu Topics über (vorher festgelegte Kommunikationskanäle, sozusagen Peer-to-Peer).
Zum Beispiel würden wir in einer Konfiguration mit mehreren Anwendungen nur mit einer bestimmten kommunizieren wollen. Statt einer „Jeder-an-Jeden“-Kommunikation, bei der fast jede Anwendung sagt: „Das ist nicht für mich“, helfen uns Topics, genau (und nur) an die beabsichtigte App zu liefern.
Auf diese Weise haben wir einen noch fortschrittlicheren Mehrkanal-Kommunikationsmechanismus erreicht, bei dem wir einen Dialog zwischen zwei bestimmten Knoten führen können, ohne andere zu berühren.
2.5. Persistierende Daten
Für einfache Aufgaben war der Persistenzmechanismus sehr einfach und nützlich. Wenn wir jedoch mehr verlangten, scheiterte die Persistenz (z. B. wegen der Gleichzeitigkeit). Mehrere Prozesse versuchten, gleichzeitig zu schreiben, konnten aber wegen der Überlastung der Anforderung nicht speichern.
Unsere Lösung war, einen „Listener“ zu implementieren: Jedes Mal, wenn etwas Neues im Speicher erscheint, legen wir es beiseite, bis wir genug davon haben, und speichern es dann alle auf einmal. Anstatt also mehrere Speichervorgänge zu machen (jeder mit “ Haben Sie die Datenbank?“ / „ist sie aktiv?“ / „ist genug Platz vorhanden?“ / „kann ich jetzt schreiben?“ / „ok, ich schreibe“), machen wir das jetzt nur einmal.
3. Weitere Schwachpunkte von Hazelcast (und Lösungen)
Für unseren speziellen Fall kam Hazelcast out-of-the-box mit ein paar suboptimalen Teilen, die aber alle schnell gelöst wurden:
3.1. Speicherauslastung / CPU-Last
Für die Fälle, in denen der Speicher oder die CPU über festgelegte Schwellenwerte hinausgehen, hat Hazelcast einen internen Überwachungsmechanismus. Da wir die eingebettete Version verwendet haben (d. h., Hazelcast und unsere App sind Teil desselben Ökosystems), konnten wir die Warnung von Hazelcast auch für unsere App verwenden. Auf diese Weise haben wir die Notwendigkeit beseitigt, ein paralleles Warnsystem zu implementieren.
Für die extremen Fälle, in denen wir trotz der Warnungen nicht in der Lage sind, den Speicher und/oder die CPU-Last zu reduzieren, schaltet Hazelcast die Dinge einfach ab – was wir auch für unsere App tun, zusammen mit einer Notmeldung an den Benutzer.
3.2. Hazelcast Verbindung abbrechen
Der Lauf in Virtualisierungsumgebungen bringt potenzielle Zeitanpassungen mit sich – es kann zu Differenzen zwischen dem CPU-Takt und dem angepassten Systemtakt der virtuellen Umgebung kommen (d. h. „Taktsprünge“). Wenn die Differenzen über einen Schwellenwert hinausgehen, initiiert Hazelcast einen Verbindungsabbruch.
Letztendlich ist dies kein großes Problem, da es mit bestimmten Konfigurationen der VMware-Virtualisierung gelöst werden kann.
3.3. Lesen aus Hazelcast mit hoher Geschwindigkeit
Allein das Lesen aus einer Map löst eine Synchronisation zwischen den Notizen aus, um zu garantieren, dass das, was gelesen wurde, wirklich die neuesten Daten sind. Als wir also unveränderliche Daten aus Hazelcast lesen mussten, haben wir einen Cache auf zweiter Schicht implementiert, der immer dann aktualisiert wird, wenn sich etwas in den Maps ändert. Das Ergebnis ist, dass das Lesen aus diesem Cache der zweiten Schicht und das Schreiben/Löschen in Hazelcast erfolgt (wodurch Ereignisse ausgelöst werden, um den Cache zu aktualisieren).
Fazit
Sich für Hazelcast zu entscheiden war die richtige Entscheidung, da es uns eine Menge Entwicklungsaufwand erspart hat (vor allem was die Kommunikation angeht). Obwohl es einige Schwachstellen gibt, können sie alle vermieden oder optimiert werden. Und das Beste daran? Es ist kostenlos!_
Sie würden gerne Ihre Erfahrungen im Bereich ZSLs / ACLs mit uns teilen? Wir freuen uns auf Ihre Kontaktaufnahme!