Memory-sharing: from basic to full-blown, with Hazelcast IMDG
Memory-sharing systems can be quite challenging. For example, the applications need the data to be shared / accessible / optimised everywhere, in real-time. This can happen with a messaging application, just as well as with employee timesheets or complex ERPs.
Developing your own dedicated solution can be done, but an easier way would be to use / integrate an out-of-the-box platform. Yes, they don’t always cover all your needs, but they can be comprehensive enough to be a good starting point that only needs minor tweaking and/or extensions.
This is consistent with our experience building with Hazelcast IMDG: we started with a relatively small usage, then discovered new tools / functions, and eventually ended up with a full-blown ecosystem.
1. Our specific case, needs, and options brought us into Hazelcast
Our specific case is a client server app, with real-time data flows from client to server. We need to join parts of the data from several machines across different networks. There is not a high payload, but we need the connection to be absolutely stable and steady. In this case, using a push/pull data communication mechanism does not help, so we need a common area where data should be placed.
The first approach was to develop a client server communication tool to include communication, merge, brain split etc. But in 2020+, we have the option of existing “packaged” solutions that we can tailor to our needs. So, instead of developing/implementing the memory-sharing system ourselves, we made a short list of existing platforms: Hazelcast, Redis, RabbitMQ, Apache Kafka.
We ended-up choosing Hazelcast, for several reasons:
First, it has a small footprint: it doesn’t take much memory, there’s no need for multiple servers – we simply embedded it in our application.
Then, it fulfilled all our basic needs:
- in-memory database,
- second-level cache,
- persisting database,
- queue implementation,
- great connection management.
Although we started with small parts, we got to add ever more: maps, shared objects, and topics. Here is what we used from / with Hazelcast:
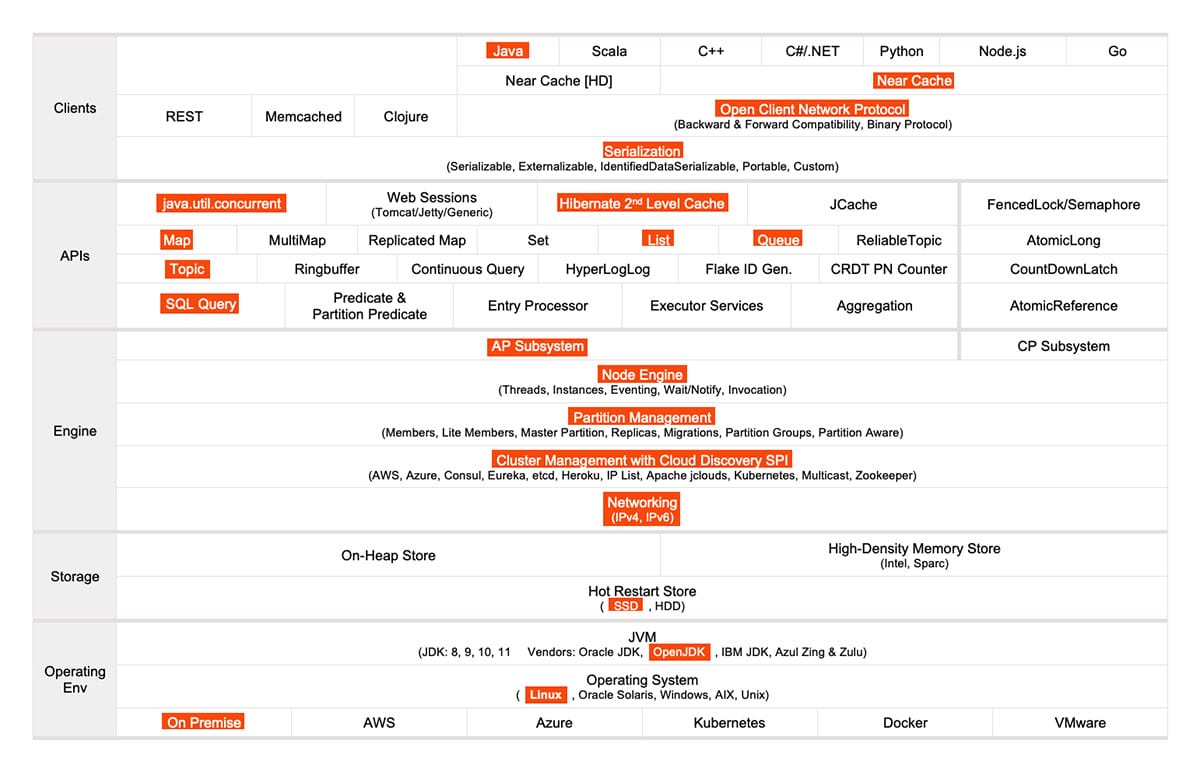
2. How we use Hazelcast
2.1. Call me to remember
Hazelcast was first raised by the server, then from each client, thus establishing a cluster.
The first phase was for us to implement an all-in-one queue, where the objects flow from clients to master. At this stage, we were only transmitting messages between applications.
An HTTP call would be sent from client to server, to do three things:
- communicate “we are here”,
- retrieve the Hazelcast cluster name,
- and establish the connection.
But then, we hit some non-standard situations:
- unusual customer architectures where HTTP calls are denied,
- the client and the server were in different networks.
Connection management is not just an afterthought. Many times, connecting applications (e.g., across geographies) takes significant time / effort / development. Especially with sensible, firewalled applications, it is quite complicated for the client company to open communication ports. Very small details can have big (and negative) impact. With Hazelcast, we got a ready-made algorithm that either finds the appropriate connections or uses the specified ports. Due to its discovery strategies, we can just tell it “go find clients within the network, then connect”.
So, we wanted to see whether Hazelcast could solve our non-standard cases – and solved it did. Regardless of whether we are in the same network or using proxies, Hazelcast is able to connect all nodes and bring up a communication channel. This solved a lot of infrastructure problems, so we made Hazelcast the standard, to replace all other communication mechanisms. Hazelcast evolved into an essential piece of the ecosystem, in such a degree that if it does not connect to the server, then the client app will not even start.
2.2. …But don’t call me too often
The next speed bump, related to latency, came up when we started moving large amounts of data into the distributed queue that’s used as a communication channel between the server (“consumer”) and the clients (“producers”). Queuing one object after another, then pooling them at the server level, added latency (which was proportional to data quantity).
Because the order of objects coming from different servers was not that important, our solution was to pack the objects into containers, then use the containers with Hazelcast. Instead of us reading thousands of individual messages and pause to check whether each of them is up to date, the client now packs and places them into Hazelcast. The result: dramatically improved performance.
2.3. Do you want more?
Solving the queue latency gave us the confidence that Hazelcast can be expanded to further areas. So, we looked into how various information (e.g., configurations) can be spread to all the nodes. We started by using Maps, initialised by the server and shared to the clients.
But managing the maps in two different places (both in Hazelcast and the database) can get complicated. There are moments when all the applications are shut, with all the info saved into the database; then at restart, all info needs to be moved back from the databased into the memory.
That’s why we switched to persisted maps and let Hazelcast to persist the data in the database, i.e., Hazelcast will save whenever optimal to do it.
2.4. …And more?
When even the maps were not enough, we moved to topics (pre-established communication channels, pretty much peer-to-peer).
For example, in a multi-application configuration, we would only want to communicate with a specific one. Instead of an “everyone to everyone” communication, where almost every application says, “this is not for me”, topics help us to deliver precisely (and only) to the intended app.
This way, we reached an even more advanced multi-channel communication mechanism, where we can have a dialogue between two specific nodes without touching any others.
2.5. Persisting data
For straightforward tasks, the persistency mechanism was very simple and useful. However, when we asked for more, the persistency failed (for example, because of concurrency). Multiple processes were attempting to write at the same time but could not save because of the request overload.
Our solution was to implement a “listener”: each time something new appears in the memory, we put it aside until we have enough of them, then save them all at once. So, instead of doing multiple saving processes (each of them with “got database?” / “is it active?” / “is there enough space?” / “can I write now?” / “ok, I write”), we now do this only once.
3. Further Hazelcast weak points (and solutions)
For our specific case, the out-of-the-box Hazelcast came with few some suboptimal parts, but all got quick solutions:
3.1. Memory exhaust / CPU load
For the cases when the memory or CPU go beyond specified thresholds, Hazelcast has an internal monitoring mechanism. Since we used the embedded version (i.e., Hazelcast and our app are parts of the same ecosystem) we could also use Hazelcast’s warning for our app. This way, we removed the need to implement a parallel warning system.
For the extreme cases when, despite the warnings, we are not able to reduce the memory and/or the CPU load, Hazelcast just shuts things down – which we also do for our app, together with a distress message sent to the user.
3.2. Hazelcast disconnect
Running in virtualisation environments comes with potential time adjustments – there can be differences between the CPU clock and the virtual environment’s adjusted system clock (i.e., “clock jumps”). When the differences go beyond thresholds, Hazelcast will initiate a disconnect.
Eventually, this is not a huge issue, as it can be fixed with specific configurations of the VMware virtualisation.
3.3. Reading from Hazelcast at high speed
Simply reading from a map will trigger synchronisation between notes, to ensure that what was read is really the latest data. So, when we needed to read immutable data from Hazelcast, we implemented a second-layer cache, to be updated whenever something changes in the maps. As a result, reading is done from this second-layer cache and the write/delete in Hazelcast (thus triggering events to update the cache).
Conclusion
Picking Hazelcast was the right thing to do, as it saved us a lot of development effort (especially when it comes to communications). Although there are some weak points, they can all be avoided or tweaked. And the best part? It’s free!
Feel like sharing your own experience with Hazelcast? Please get in touch!