Gatling Leistungstests und Integration in die GitLab CI/CD-Pipeline
Wenn CD/kontinuierliche Entwicklung und Bereitstellung von Funktionen mit sehr hoher Geschwindigkeit erfolgen, ist es entscheidend, dass die Systemleistung innerhalb der definierten Grenzen bleibt. Im Folgenden erfahren Sie, wie wir Gatling Leistungstests entwickelt und in unsere GitLab CI/CD-Pipeline integriert haben.
Dieser Artikel befasst sich mit folgenden Themen:
- Welche Tools für die Durchführung des Leistungstests zu verwenden sind
- Wie man den Leistungstest entwickelt
- Wie die GitLab-Pipeline eingerichtet wird
- Welche Endpunkte auf welcher Infrastruktur getestet werden sollen
- Aufbereitung der Daten für die Tests
Einführung
Nichtfunktionale Anforderungen
Ein paar Worte über die zu testende Anwendung
Bei dem zu testenden System handelt es sich um eine Sammlung von Microservices, die in einer Hochverfügbarkeitskonfiguration auf dem Open Telekom Cloud Provider laufen und deren Persistenz durch relationale MySql-Datenbanken sichergestellt wird. Die Anwendung ist auch mit anderen Systemen wie SAP, SalesForce und Enterprise Content Management System über Rest-Schnittstellen, Hooks und Dateien verbunden.
Die Server und Dienste werden mithilfe von Terraform und Ansible über einen Infrastructure-as-a-Code-Ansatz aufgesetzt. Docker wird verwendet, um die Anwendung in mehrere Container zu verpacken.
CI/CD wird mit GitLab eingerichtet.
Der Tech-Stack besteht hauptsächlich aus Java mit SpringBoot und Hibernate, Hazelcast, JHipster, Angular mit Typescript, sowie Docker und K8s.
Was sind Leistungstests?
Verwendete Tools
Für die Durchführung der Leistungstests haben wir Gatling verwendet, weil es einfach zu bedienen ist, sich gut in CI/CD-Tools und DevOps-Prozesse integrieren lässt und sofortige Berichte liefert.
Der in Chrome verfügbare Gatling-Recorder wurde manchmal als Ausgangspunkt für die Entwicklung von Testszenarien verwendet.
Scala wurde zum Schreiben der Leistungstestszenarien verwendet und Gradle war unser Build-Tool.
Docker wurde verwendet, um unsere Anwendung als Container zu verpacken, und Gitlab wurde für die CI/CD-Pipelines mit unseren konfigurierten Runnern verwendet.
Zur Vorbereitung der Testdaten verwendeten wir das Spock-Framework mit in Groovy geschriebenen Testszenarien.
Warum sollten Leistungstests in die CI/CD-Pipeline integriert werden?
Es ist wichtig sicherzustellen, dass die Systemleistung innerhalb der definierten Grenzen bleibt, wenn die kontinuierliche Entwicklung und Bereitstellung von Funktionen mit einer sehr hohen Geschwindigkeit erfolgt.
Wenn die Tests fehlschlagen, wissen wir, dass ein Teil des neuen Codes die Leistungsbeschränkungen verletzt hat. Grundsätzlich werden die automatischen Leistungstests bei jeder Zusammenführung eines Funktionszweigs mit bestimmten Umgebungszweigen durchgeführt. Auf diese Weise haben wir die Gewissheit, dass die Leistung für die sensiblen oder abgedeckten Szenarien nicht beeinträchtigt wurde, bevor die neue Version in der Produktion eingesetzt wird.
Einführung in Gatling
Aufnahme-Modus
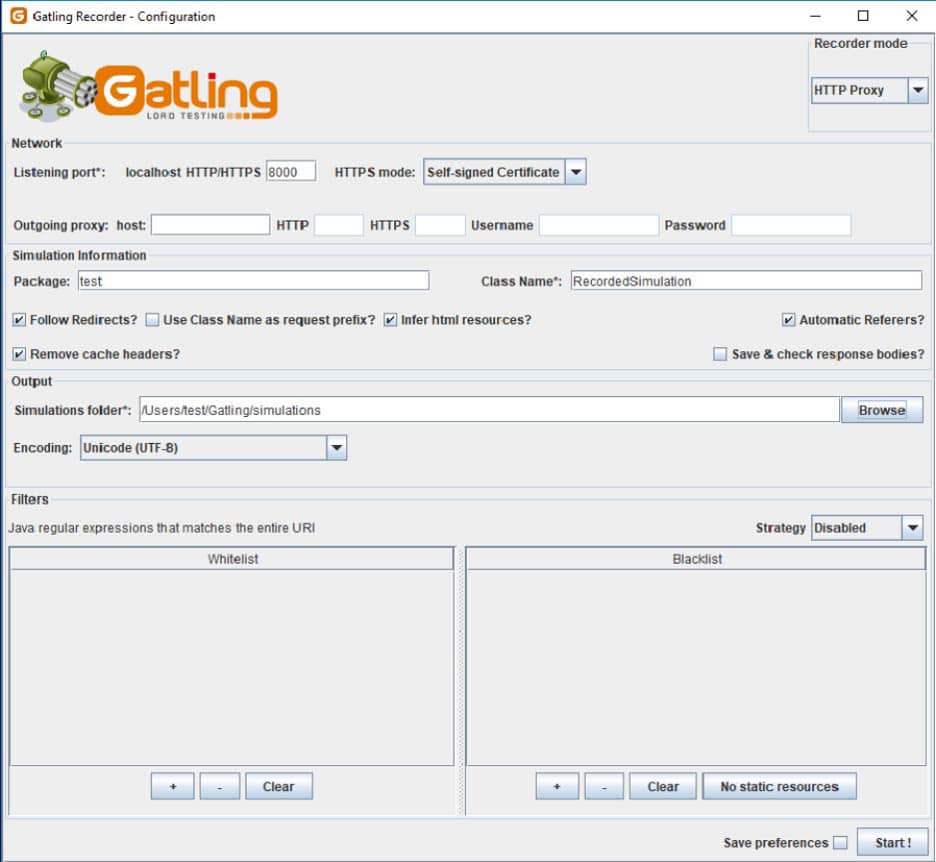
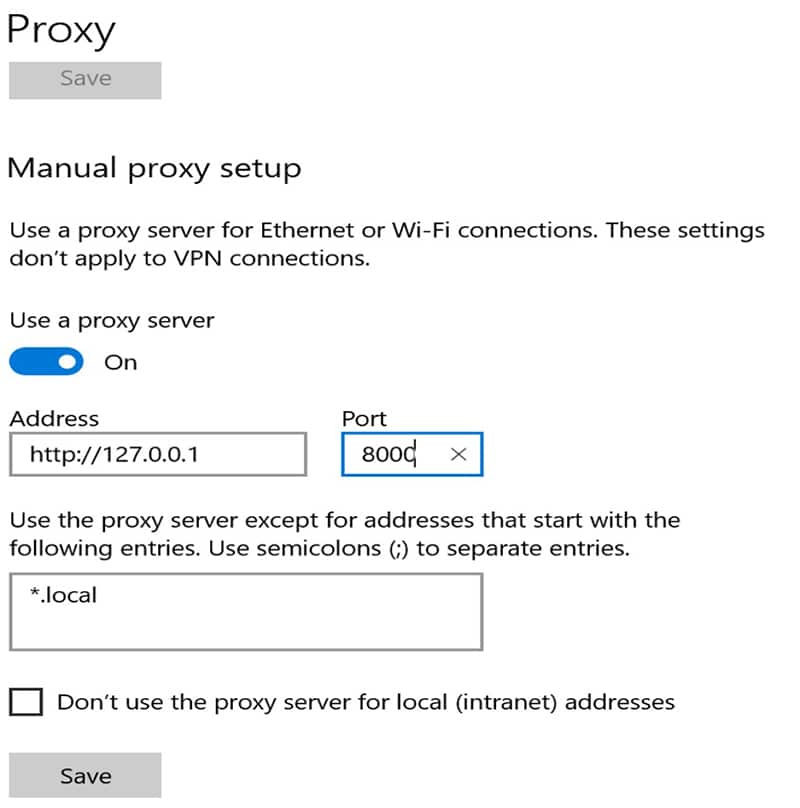
Dieser Bildschirm hängt von dem verwendeten Betriebssystem ab. Danach sollte sich der Browser mit diesem Port verbinden.
Während der Benutzer im Browser navigiert, zeichnet der Rekorder die Anfrage auf, pausiert und generiert am Ende den Simulationscode. Es gibt Filter, die definiert werden können, um bestimmte Anfragen herauszufiltern – zum Beispiel alle Anfragen nach css-Dateien. Außerdem können SSL-Zertifikate für den https-Modus bereitgestellt oder on the fly generiert werden.
Der generierte Code kann als Ausgangspunkt für die Entwicklung der Leistungssimulation verwendet werden, muss aber überarbeitet werden, um wartbarer zu sein, nicht benötigte Anfragen zu ignorieren und die richtigen Korrelationen und Abstraktionen herzustellen.
Simulationen
Der Einstiegspunkt eines Leistungstests ist eine Simulation. In einem einzigen Durchlauf können die auszuführenden Simulationen konfiguriert werden. Die Simulation ist das Äquivalent zu einem Testfall in der beliebten Junit-Bibliothek. Sie verfügt über Setup- und Teardown-Methoden, aber auch über Hilfsmethoden zur Durchführung von Assertions und zur Speicherung globaler Werte.
class MyInteractionsTest extends Simulation {
val context: LoggerContext = LoggerFactory.getILoggerFactory.asInstanceOf[LoggerContext]
// Log all HTTP requests
context.getLogger("io.gatling.http").setLevel(Level.valueOf("TRACE"))val httpConf = http
.baseUrl(PerfConstants.baseURLServer)
.inferHtmlResources()
.header("Origin", PerfConstants.baseURLServerWeb)
.acceptHeader("application/json, text/plain, application/hal+json, application/problem+json, */*")
.acceptEncodingHeader("gzip, deflate")
.acceptLanguageHeader("en,en-US;q=0.9,ro-RO;q=0.8,ro;q=0.7,de;q=0.6")
.connectionHeader("keep-alive")
.userAgentHeader("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")
.disableWarmUp
.silentResources // Silence all resources like css or css so they don't clutter the resultsHier konfigurieren wir das http-Protokoll. Wir richten die http-Header mit den erwarteten Werten ein und simulieren die Browseranfragen. Der Origin-Header wird auf die angegebene Server-URL gesetzt, um CORS-Probleme zu vermeiden. Die statischen Ressourcen, wie z. B. css-Dateien, und ihre Fehler erzeugen eine Menge Lärm, so dass wir die Berichterstattung für sie über das silentResources-Flag deaktivieren wollen.
Das Ableiten der Html-Ressourcen bedeutet, dass das Verhalten des Browsers beim asynchronen Laden der eingebetteten Ressourcen wie Skripte, Links, Bilder, Frames, Objekte usw. nachgeahmt werden soll.
val headers_http_authenticated = Map(
"Content-Type" -> """application/json""",
"Accept" -> """application/json, application/hal+json, application/problem+json""",
"Authorization" -> "${access_token}",
)Für verschiedene Anfragen benötigen wir möglicherweise unterschiedliche Kopfzeilen. Die obige Variable enthält die Header für eine authentifizierte Anfrage. Das Zugriffs-Token wird als Wert für den Autorisierungs-Header bereitgestellt. Das Token wurde zuvor bei einer Anmeldeanfrage in einer virtuellen Benutzersitzung über einen Mechanismus namens Checks gespeichert. Die Checks werden verwendet, um die Anfragen zu validieren und Werte zu extrahieren, die später wiederverwendet werden können.
Eine solche Login-Anfrage kann wie folgt aussehen:
object Login {
val headers_http_authentication = Map(
"Content-Type" -> """application/json""",
"Accept" -> """application/json, application/hal+json, application/problem+json""",
)
val login =
exec(http("Authentication")
.post("/auth/token")
.headers(headers_http_authentication)
.body(StringBody("""{"username":"adm@project.com", "password":"*****"}"""))
.check(status.is(PerfConstants.HTTP_STATUS_OK))
.check(header("Authorization").saveAs("access_token"))
).exitHereIfFailed
}Es gibt ein Login-Anforderungsobjekt mit einer Kopfzeile für nicht authentifizierte Benutzer, die keine Token enthält.
Über die exec-Methode wird ein http-Post-Aufruf an den Endpunkt /auth/token ausgeführt, der die Anmeldedaten im Body enthält. Die Prüfkonstrukte validieren den Antwortstatus und speichern das zurückerhaltene Zugriffstoken in der Kopfzeile der Autorisierungsantwort.
Die Anfrage kann als Teil eines Szenarios über eine fluent api ausgeführt werden:
val scn = scenario("My interactions")
.exec(Login.login).exitHereIfFailedval scn = scenario("My interactions")
.exec(http("First unauthenticated request")
.get("/auth/user")
.headers(headers_http)
.check(status.is(401))
).exitHereIfFailed
.pause(3)
.exec(Login.login
).exitHereIfFailed
.pause(2)
.exec(http("Authenticated request")
.get("/auth/user")
.headers(headers_http_authenticated)
.check(status.is(200)))
.pause(3)
.exec(NavigationTree.navigationTree)
.exec(MyInteractions.myInteractions)Nach jeder Anfrage können Prüfungen durchgeführt werden, die bei Nichterfüllung der Bedingungen abgebrochen werden. Es können auch Pausen eingefügt werden, um einen menschlichen Benutzer zu simulieren.
Die anderen Szenario-Anfragen sehen ähnlich aus wie die Login-Anfrage, verwenden aber andere http-Methoden und Prüfungen.
val navigationTree =
exec(http("Navigation EndPoints")
.get(PerfConstants.baseURLServer + " /navigationTree ")
.headers(headers_http_authenticated)
.check(status.is(PerfConstants.HTTP_STATUS_OK))
.check(jsonPath("$.mainObjects[0].mainObject.aid").saveAs("firstOrder")))
.pause(PerfConstants.PAUSE_BETWEEN_REQ_IN_SEC)Für einen authentifizierten Benutzer wird eine get-Anfrage durchgeführt, und der Wert aus der geparsten json-Antwort wird in der virtuellen Sitzungsvariablen namens firstOrder gespeichert.
Jedes Szenario hat eine Einrichtungsphase, in der die Anzahl der gleichzeitigen Benutzer und die Anlaufzeit festgelegt werden.
setUp(scn.inject(rampUsers(20) during (2 seconds))).protocols(httpConf)
In unserem Fall führen 20 Benutzer dasselbe Szenario aus, und alle beginnen im Abstand von 2 Sekunden mit der Erstellung der ersten Anfrage. Das bedeutet, dass nach zwei Sekunden mindestens 20 Anfragen in Bearbeitung sein werden.
Die Ausführung des Szenarios beginnt mit dem Konstrukt:
scenario("My navigation").exec(scn)Erwartete Schwellenwerte
Erwartete Antwort-/Zeitschwellenwerte können global für alle Anfragen oder Szenarien, aber auch für einzelne Anfragen festgelegt werden. Die Werte müssen auch die Infrastruktur berücksichtigen, auf der die Tests laufen, und müssen entsprechend angepasst werden. In der Regel ist die Produktionsinfrastruktur leistungsfähiger als die der anderen Umgebungen. Es war keine leichte Aufgabe, die richtigen Werte zu definieren, die uns auch die erwarteten Werte in der Produktion liefern.
In der Phase der Szenarioeinrichtung werden auch die erwarteten Schwellenwerte definiert:
setUp(scn.inject(rampUsers(20) during (2 seconds))).protocols(httpConf)
// Assert that every request has no more than 1% of failing requests
.assertions(forAll.failedRequests.percent.lte(1))
// Assert that the max response time of all requests is less than 5000 ms
.assertions(global.responseTime.max.lt(PerfConstants.MAX_RESPONSE_TIME_MS))
// Assert that the max response time of authentication requests is less than 3000 ms
.assertions(details("Authentication").responseTime.max.lt(PerfConstants.MAX_RESPONSE_TIME_AUTH_MS))
// Assert that the max response time of the navigation tree requests is less than 5000 ms
.assertions(details("Navigation tree").responseTime.max.lt(PerfConstants.MAX_RESPONSE_TIME_MS))
// Assert that the max response time of the my interactions requests is less than 5000 ms
.assertions(details("My interactions").responseTime.max.lt(PerfConstants.MAX_RESPONSE_TIME_MS))Mit dem Konstrukt forAll kann man Assertions für alle Anforderungen bestimmter Typen durchführen, z.B. für fehlgeschlagene Anforderungen.
Behauptungen können auch für alle Anfragen eines beliebigen Typs mit dem Konstrukt global gemacht werden.
Für eine bestimmte Anforderung, die durch den Pfad identifiziert wird, können Aussagen mit der Anweisung details(„request group / request path“) gemacht werden.
Weitere Aussagen können über Metriken wie die Anzahl der erfolgreichen Anfragen oder die Anzahl der Anfragen pro Sekunde gemacht werden. Zum Vergleich stehen Zähl- oder Prozentwerte zur Verfügung, wobei mehrere Bedingungen miteinander verkettet werden können. Vergleichsoperatoren wie between, around und deviatesAround(target, percent) sind verfügbar.
Einrichten der GitLab-Pipeline
Die Pipeline wird in der Datei .gitlab-ci.yml konfiguriert, die sich im Stamm des Leistungstestprojekts befindet.
Es gibt eine einzige Stufe namens test.
stages: - test
Zu verwendendes Docker-Image
Eine Herausforderung bestand darin, ein Docker-Image zu finden, das alle benötigten Scala- und Gatling-Bibliotheken enthält und ohne großen Aufwand verwendet werden kann. Der Gitlab-Runner sollte in der Lage sein, dieses Image zu ziehen, den Code auszuchecken und die Tests über ein Bash-Skript zu starten.
Nach mehreren Versuchen haben wir das Image koosiedemoer/netty-tcnative-alpine gefunden, das in unserer Umgebung funktioniert.
perftest-master: image: koosiedemoer/netty-tcnative-alpine stage: test
Auslöser der Ausführung
Es gibt zwei Ereignisse, die die Ausführung der Leistungstests auslösen.
Das eine Ereignis ist die Übergabe des Leistungstestprojekts an unseren Master-Zweig.
perftest-master:
…
only:
- master
except:
variables:
- $EXECUTE_TEST_FOR_ENVIRONMENT =~ /^TEST/Der Schritt wird nur auf dem Master-Zweig ausgeführt, wenn die Umgebungsvariable EXECUTE_TEST_FOR_ENVIRONMENT nicht definiert ist oder nicht mit TEST beginnt. Die Variable wird verwendet, um festzustellen, ob ein externer Auslöser die Ausführung verursacht hat – für den Fall, dass wir eine andere Aktion/Konfiguration durchführen müssen.
Das andere Ereignis tritt ein, wenn es extern nach einem bestimmten Schritt in einer anderen Projektpipeline aufgerufen wird.
perftest-master:
stage: perftest
image: registry.gitlab.com/finestructure/pipeline-trigger
script:
- apk --no-cache add bash curl
- ./ci/bin/perf-trigger.sh
tags:
- perftrigger
only:
- masterIn einem Microservice-Projekt wird in der gitlab ci-Pipeline-Konfigurationsdatei eine perftest-Phase definiert, die das pipeline-trigger-Docker-Image abruft, die erforderlichen Pakete installiert und das ausgecheckte Skript perf-trigger.sh ausführt.
Dieser Schritt wird nur ausgeführt, wenn ein Commit auf dem Master-Branch vorliegt, und erst nachdem die vorherigen Pipeline-Stufen ausgeführt wurden.
Die Bash-Datei enthält etwas wie:
trigger -a ${APP_GITLABTRIGGER_APITOKEN} -p ${APP_GITLABTRIGGER_PERFTESTTOKEN} -t ${branch} ${APP_GITLABTRIGGER_PERFTESTID} -e EXECUTE_TEST_FOR_ENVIRONMENT=TESTDas Docker-Image enthält den Trigger-Befehl, bei dem Gitlab-Tokes bereitgestellt werden, die Ziel-Pipeline, den Zweig und die Umgebungsvariablen.
Im Leistungstestprojekt kann eine weitere Stufe nur für den externen Auslöser definiert werden.
perftest-master-ext:
…
only:
- master
only:
variables:
- $EXECUTE_TEST_FOR_ENVIRONMENT =~ /^TEST/Einrichtung der Ausführung
perftest-master:
…
script:
- apk --no-cache add bash
- ./bin/testperf.sh "https://apistage.domain.net"
tags:
- perftests
artifacts:
when: always
paths:
- build/reports/gatling/*
expire_in: 1 week
…Im Skriptabschnitt werden die fehlenden Pakete im laufenden Container installiert und die Bash-Datei testperf.sh wird unter Angabe der Stage-Umgebung als Basis-API-URL ausgeführt.
Der Tag identifiziert das Label für den Gitlab-Runner, der die Tests ausführen wird.
Der Abschnitt artifacts konfiguriert das Ziel für die Speicherung der Berichte und wie lange sie zum Herunterladen zur Verfügung stehen sollen.
Die Bash-Datei startet den gradle-Befehl zur Ausführung des Tests in der angegebenen Umgebung:
./gradlew gatlingRun -DbaseURL=]
In der gradle.build-Datei verwenden wir das Gatling-Plugin und konfigurieren, welche Tests ausgeführt und wo die Berichte gespeichert werden sollen, wie im Folgenden dargestellt:
plugins {
id "com.github.lkishalmi.gatling" version "3.0.2"
}
…
apply plugin: "com.github.lkishalmi.gatling"
..
gatling {
…
simulations = { include "**/*Test.scala" }
}
task testReport(type: TestReport) {
destinationDir = file("$buildDir/reports/tests")
reportOn test
}
…Vorbereitung der Daten und der Infrastruktur für die Durchführung der Tests
Auf welchen Systemen sollen die Tests ausgeführt werden?
Es gibt mindestens zwei Möglichkeiten, dies zu tun. Eine Möglichkeit besteht darin, eine neue Umgebung einzurichten und die Anwendung in dieser sauberen Umgebung mit einer genau definierten Konfiguration und Kapazität einzusetzen. Eine andere Möglichkeit besteht darin, den Leistungstest in einer bestehenden Umgebung mit fester Kapazität und bekannter Konfiguration durchzuführen.
Sie können die Tests auch von Zeit zu Zeit in der Produktionsumgebung durchführen, wenn Sie es sich leisten können, sie zu skalieren oder ein Zeitfenster (Wartungsfenster) zu finden, in dem die Benutzer nicht gestört werden.
Wir haben uns dafür entschieden, die Leistung mit unserer Staging-Umgebung zu testen, da diese mit unserer Produktionsumgebung vergleichbar ist und wir nicht darauf warten wollten, eine weitere saubere Umgebung zu erstellen. Außerdem werden die Produktionsbenutzer durch die häufige Ausführung der Tests nicht beeinträchtigt.
Welche Endpunkte sind zu testen?
Jede Anwendung hat ihre eigenen Besonderheiten und löst klare Geschäftsanforderungen. Die am häufigsten verwendeten Geschäftsszenarien müssen getestet werden, um sicherzustellen, dass die Anwendung innerhalb der vereinbarten Leistungsparameter bleibt. Außerdem müssen die Aktivitäten berücksichtigt werden, die die Leistung am stärksten beeinträchtigen können.
Ein anderer Ansatz wäre die Verwendung von Überwachungswerkzeugen, um die Benutzeraktivitäten zu verfolgen und dann die kritischen Punkte und die Antwortzeiten der Anwendung zu analysieren, um zu entscheiden, welche Leistungstests geschrieben werden sollen.
Wir haben beide Ansätze angewandt und gute Kandidaten identifiziert, wie z. B. die Authentifizierungsendpunkte, die Berechtigungsprüfung, einige umfangreiche Ressourcenlisten und Teile der Geschäftslogik.
Auffüllen der Daten
Bei den Daten für den Leistungstest kann es sich um ein Backup der Produktionsdatenbank handeln, das in angemessener Zeit wiederhergestellt werden kann.
Falls eine bestehende Umgebung für die Durchführung des Leistungstests verwendet wird, können sich einige Testbenutzer authentifizieren und die Szenarien durchführen.
In unserem Fall verwenden wir die von unseren Integrationstests erstellten Testbenutzer und Daten. Dies ist eine Voraussetzung. Unsere Integrationstests werden in Groovy unter Verwendung des Spook-Frameworks entwickelt und führen http-Anfragen aus, die unsere REST-APIs aufrufen, um die Daten aufzufüllen.
Spook-Tests können wie die beliebten JUnit-Tests geschrieben werden. Es gibt eine Basisklasse namens Specification, die erweitert werden kann und Hilfsmethoden für Mocking, Stubbing und Spying bietet. Sie ist äquivalent zu einem Testfall von Junit.
class BaseSpec extends Specification {
@Shared
public static HttpBuilder clientFür die Ausführung der API-Aufrufe wird eine Art Groovy-Http-Client verwendet. Der Client wird mit einer Hilfsserialisierungsbibliothek namens JsonSlurper konfiguriert. Die Methoden können der Reihe nach ausgeführt werden, wenn wir die @Stepwise-Annotation verwenden.
Es gibt Setup- und Cleanup-Methoden, die vor jeder Testmethode ausgeführt werden, und setupSpec und cleanupSpec, die vor und nach jeder Spezifikation ausgeführt werden.
Ein Beispiel für die setup-Methode kann den http-Client initialisieren und den Admin-Benutzer anmelden.
def setupSpec() {
client = HttpBuilder.configure {
request.uri = BASE_URL_SERVER
request.setContentType('application/json')
response.success { resp, data ->
if (data != null){
}
}
…
loginAs(admin)
}def 'give ROLE_ADMIN privilege to the user'() {
given: 'a valid ADMIN privilege'
def privilege = [
scope : 'RESOURCE',
key : 'ROLE_ADMIN',
user : [
aid: userAid
],
role : [
aid: ROLE_ADMIN_LICENSE
],
resource: [
aid: ROOT_COMPANY_AID
]
]
when: 'I post the privilege'
def response = client.post {
request.uri.path = '/privileges'
request.body = privilege
}
then: 'the privilege was created'
assertResponseStatus(response, 201)
}
Es wird eine privilegierte Anfrage erstellt und ein http POST an den Server gesendet. Am Ende wird der 201-http-Status geprüft, es kann aber auch die Struktur der Antwort geprüft werden.
Mehrere Spezifikationen können in einer Testsuite gruppiert und auf einmal ausgeführt werden.
@RunWith(Suite.class)
@Suite.SuiteClasses(
[
AnInitTestSuiteSpec,
AnotherWorkflowSpec
]
)
class TestSuite {
}test{
systemProperty "target", findProperty("target")
systemProperty "targetServer", findProperty("targetServer")
testLogging {
exceptionFormat = 'full'
}
filter {
//specific test method
includeTestsMatching "specs.TestSuite"
}
}Berichte über Leistungstests
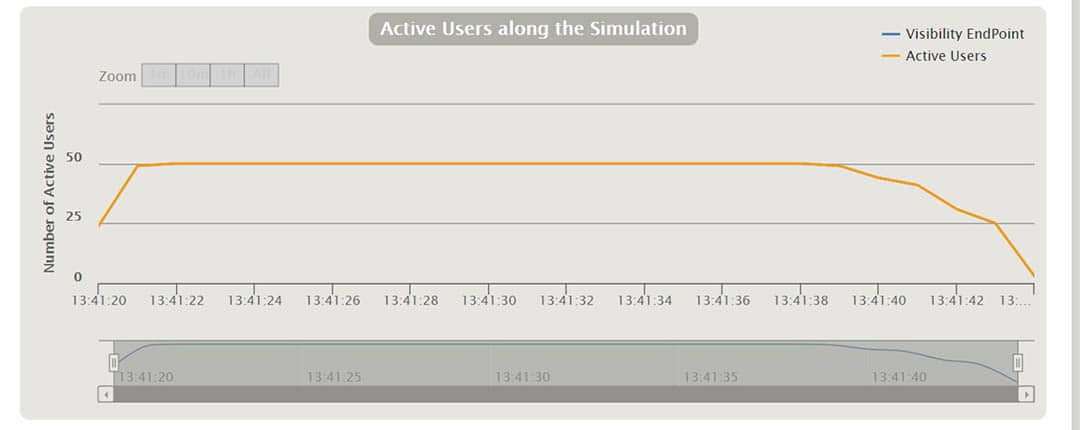
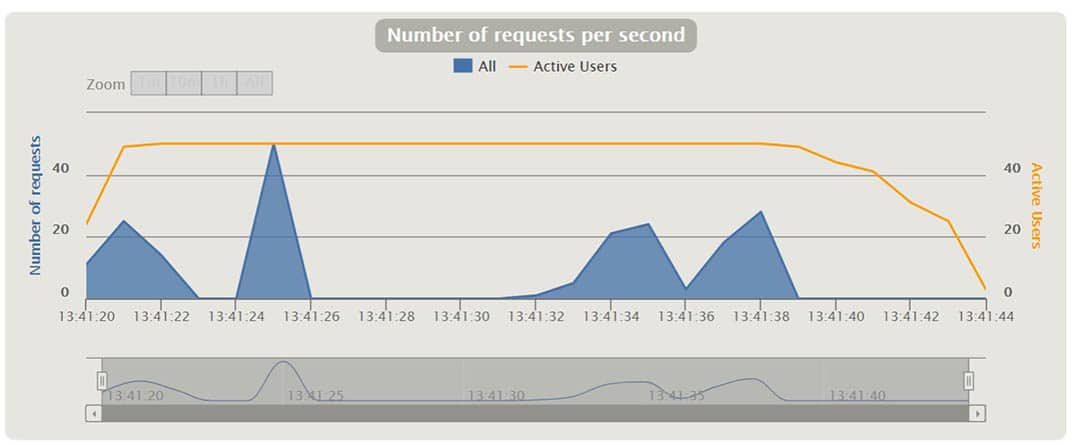
Gatling erstellt nach der Ausführung der Szenarien eine Reihe von Berichten. In den Diagrammen können wir Dinge wie Antwortzeit, Anfragen pro Sekunde, Durchsatz, mittlere Zeiten und Perzentile über Zeit und Benutzer verteilt sehen. Mit einigen der Diagramme kann man interagieren und zusätzliche Informationen als Tooltip anzeigen oder das Zeitintervall vergrößern und verkleinern. Im Folgenden werde ich einige davon anhand verschiedener Szenarien erläutern.
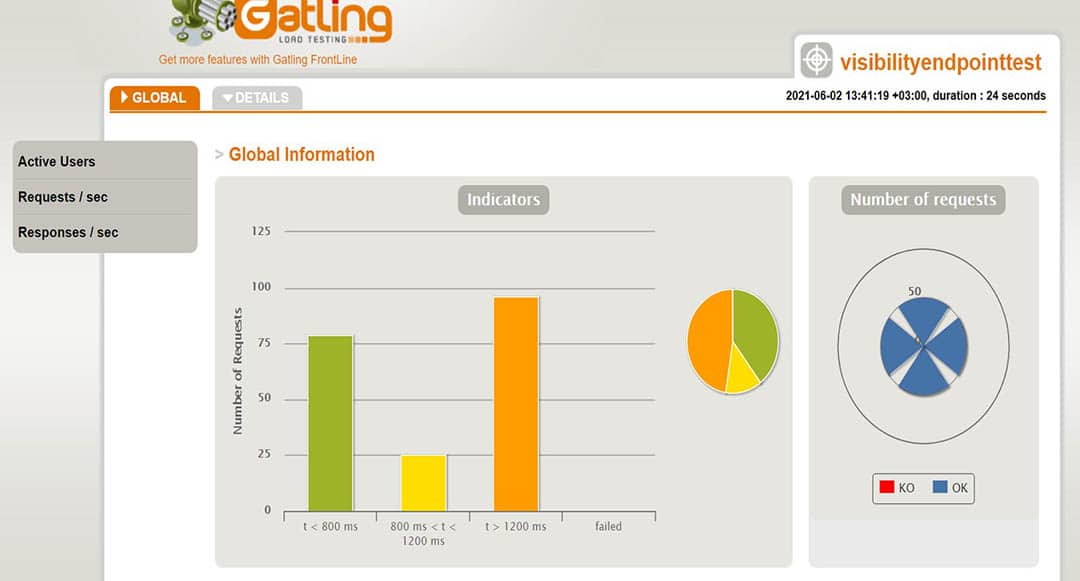

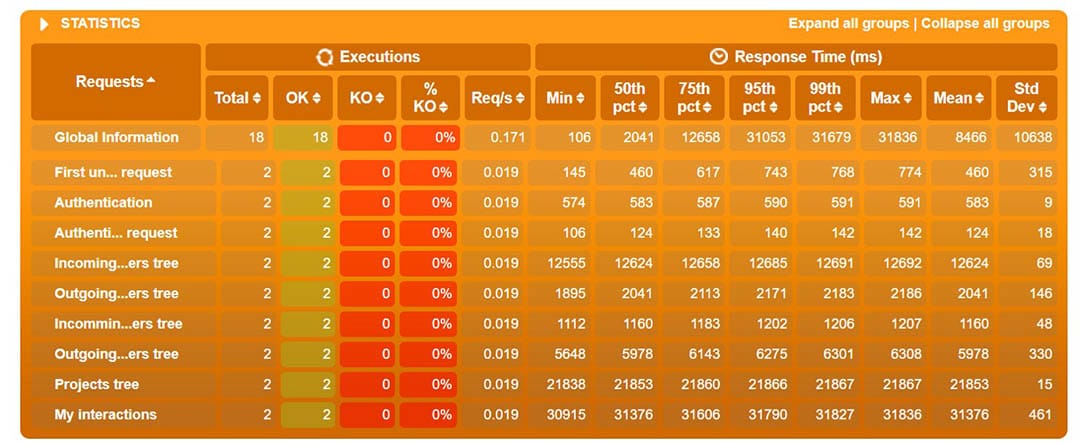
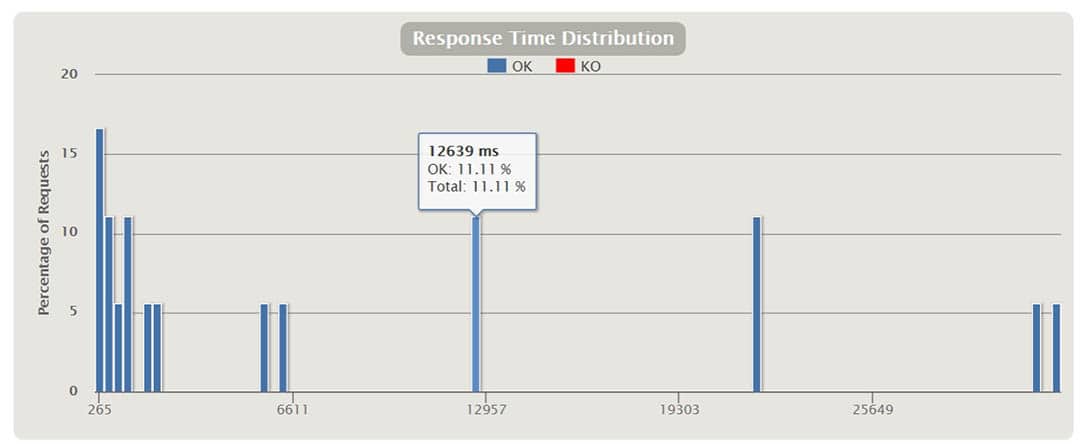
Das obige Diagramm zeigt den prozentualen Anteil der Antwortzeiten, verteilt auf Zeitspannen in Millisekunden.
So ist beispielsweise zu erkennen, dass 17 % der Anfragen rund 265 ms benötigten.
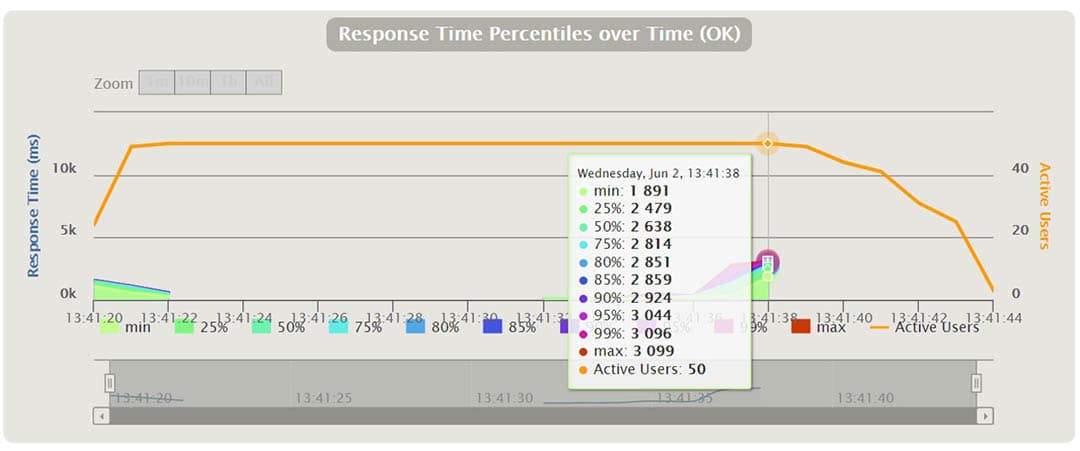
An einem bestimmten Punkt des obigen Diagramms können wir die Prozentsätze der laufenden Anfragen und ihre Antwortzeit in ms sehen. Wir können das Zeitintervall vergrößern und verkleinern.
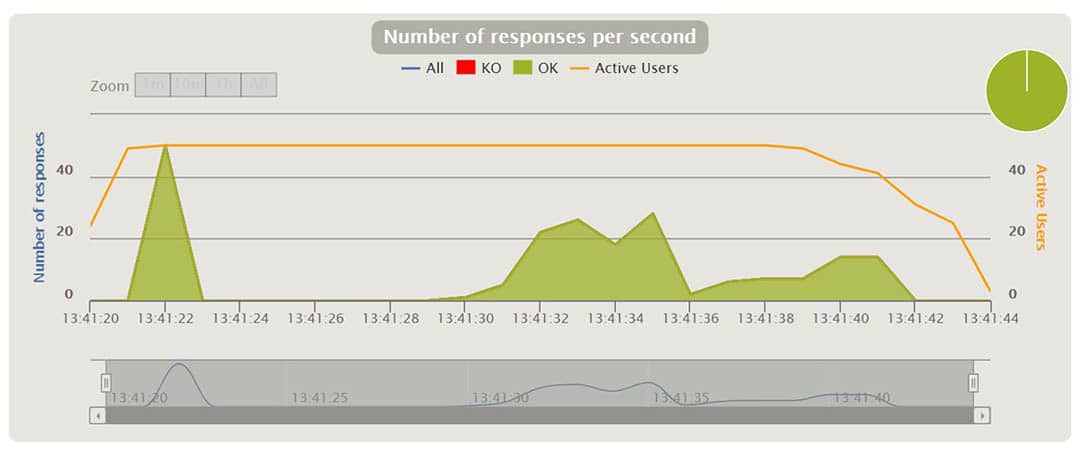
Schlussfolgerungen
Es war eine Herausforderung, Leistungstests regelmäßig in die CI/CD-Pipeline zu integrieren und durchzuführen. Wir haben hier über einen Weg berichtet, der für uns funktioniert hat. Wir haben auch die Herausforderungen, mit denen wir konfrontiert waren, sowie die verwendeten Tools angesprochen. Außerdem haben wir versucht Einblick in die Art und Weise, wie wir die Tests schreiben und wie wir die Daten für sie vorbereiten, zu gewähren. Wir hoffen, dass die von uns bereitgestellten Informationen für Sie hilfreich waren!
Sollten Sie Fragen haben, freuen wir uns auf Ihre Kontaktaufnahme unter contact@bergsoftprod.wpengine.com.
***
Und wie machen Sie das? Möchten Sie Ihre Lösung mit uns teilen?