Digitalisation „How to”: Software product development/management (3/6)
The development of a digital solution/product usually starts once its value is clarified/confirmed. Especially for non-bootstrapped projects, it can get quite capital-intensive to build things that are eventually confirmed as value-less.
Assuming that the value of your software solution/product is confirmed, let’s have a quick look into the actual software development flows, and the way they sync with your business:
- Establishing the functions/features setup
- Technology selection
- Architecture definition
- Tasks, to dos, planning
- Capacity
- Development
1. Establishing the functions/features setup
Your software needs to perform precise functions and include specific features, in order for it to deliver value to users/clients. These might be clear in your business scenario, but they still need to be translated into requests to the software development team/company.
That’s why the developers will start by discussing and understanding your business goals, as well as your software’s target functions and features. This is the first step within a repetitive cycle made of:
[ clarify the functions/features ]
↓
[ choose the appropriate technologies ]
↓
[ define the architecture ]
↓
[ execute tasks ]
↓
[ repeat ]
The result will be a level-zero plan / roadmap (such as this example, for a commercial solution):
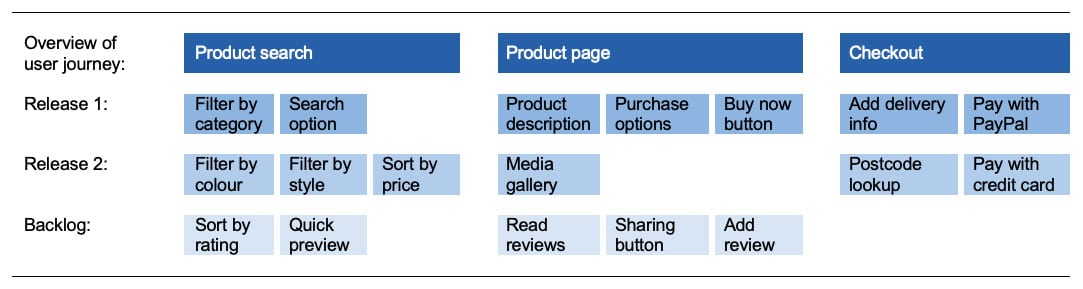
The usual timeline for a release is few months, to be usually split into short iterations (1-2 weeks each).
One possible risk is for you to specify too many functions/features, with all of them equally important. Although the software development team should not have a say in your business goals, they can still support you with building the user story mapping and in prioritising the feature tree. This way, there’s a higher chance for you to focus on the most important elements.
2. Technology selection
Once the functions and features are clearer, the technology selection is usually up to the software development team, unless you have specific constraints. For example, you might already have an Azure account/subscription, in which case it makes more sense to stay within the ecosystem than move over to AWS. Or your maintenance team already uses .NET, which makes Java a non-choice.
The chosen technology should be future proof, i.e. to be still usable for a foreseeable, reasonable period of time. But although choice of technology should be stable, there will be situations where further iterations/changes are needed.
Take, for example, one of Berg Software’s recent projects involving Big Data: our first approach was SQL, but the client needs ran into restrictions (data volume, speed, maintenance). We therefore moved into two new technologies (ClickHouse, Elasticsearch), and ended-up using each for a separate part of client’s custom-made software.
3. Architecture definition
Architecture and technology go hand in hand. The only reason why we had technology first is that many times, it can influence big parts of the architecture. Think, for example, of how choosing to work in the cloud is shaping your architectural choices.
The way we work is to first define the “high level” architecture of the big elements (e.g., frontend, backend, possibly some separate services such as authentication, reporting etc.). Then, we split these into modules with their detailed, local architectures.
By setting up a modular architecture, we make sure that it’s adaptable to future iterations. Just like technology, architecture is not something you change every few weeks – but there will be situations when change is needed.
For example, your software might initially include dedicated authentication, with its own clearly defined users and roles. But then, you can decide that if users are already logged into your existing ERP, OS etc., they should also use that authentication for the new software. In this case, the local authentication architecture will be reset, possibly to include an API to your other software assets.
4. Tasks, To Dos, Planning
Now that functions and features, technology and architecture are clear, we can start developing based on a release plan and an iteration plan. Here’s what goes into each of them:
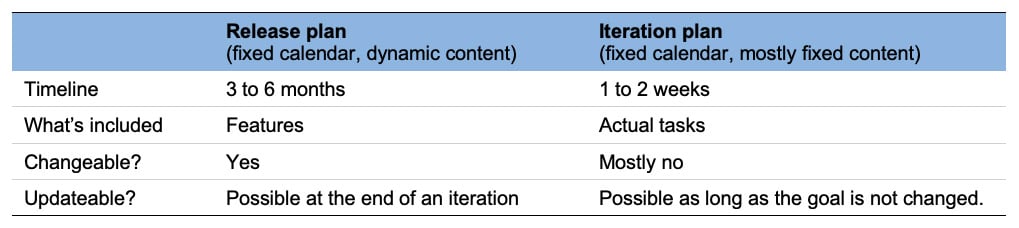
Active planning should be done for both the releases and the iterations.
Once an iteration is finalised, it can impact the release plan. Elements such as the business logic, or legal request, or technical issues can slow things down – therefore the release plan might also be changed to include a trimmed / reordered feature set. Regardless of the features list, the release timeline will stay mostly unchanged.
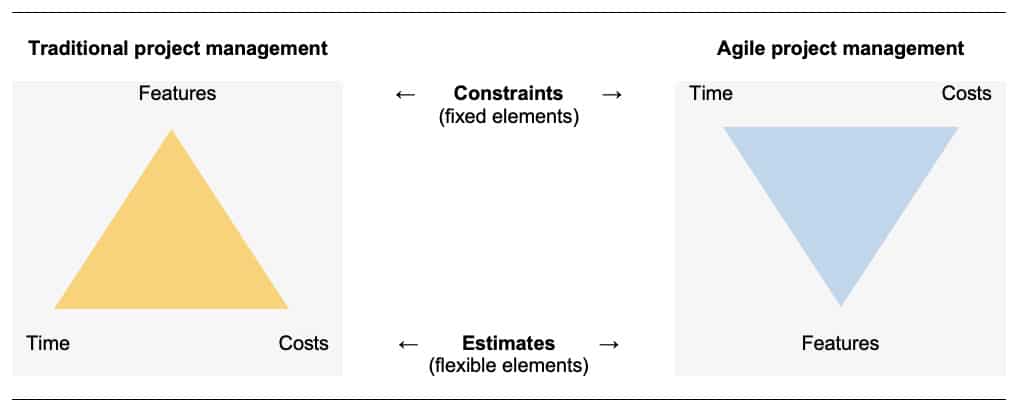
Based on Agile principles, the main constrains (/stable elements) are Time and Costs, while the variable one is Features. This is different from the traditional project management, where Features are fixed, and Time and Costs are variable (i.e., usually increasing).
5. Capacity
To execute the plan, one needs time and resources – in this case, workforce capacity. And especially when it comes to software, things can get quite challenging.
First, there is a chance that your internal team will partner with an external service provider, in a software outsourcing setup that provides flexible access to skills.
You will have a product owner and/or a team to provide the internal know how and keep in permanent contact with the development team/company. Your team should know the inside-outs of the software product/solution being developed, although not architecting/developing it themselves.
Then, the actual development team should start with a minimal number of key people with significant experience with the technologies used by your software product/solution. Scaling the development team can be treated in the same iterative manner, i.e. increase/allocate resources once the picture is clearer (technologies, architecture, plan) and execution needs to be ramped-up. It might be a matter of personal preference, but we found out that having a nucleus of people who previously worked together helps moving things smoother.
6. Development
Working in small, frequent iterations has its own benefits, but it is only a part of a bigger picture. At Berg Software, we do software development based on Agile/Lean principles, and Continuous Delivery/Continuous Integration flows.
What does this mean?
First, we build quality in. Our culture, people and tools allow us to detect issues straight away, when it is easier and cheaper to resolve.
This is possible due to continuous testing: automated tests are executed against every commit, to provide quick feedback on all changes. Work is not done until all relevant automated tests are passed.
Then, when we split the work in small batches, we are able to deliver outcomes quickly. At the same time, it helps us to frequently get feedback and correct the course.
Our people do higher-value problem-solving, and the computers perform repetitive tasks. Repetitive tasks are automated, in order for the software developers to be free for creative work, ideally on a growing tech stack.
Last but not least, we pursue continuous improvement. Everyone is responsible and collaborates for ever-higher performance of the software solutions/products we deliver.
—
Conclusion
Before any code is written: make sure that the software development team understands your business goals and desired functions/features set, then translates them into building blocks such as technologies, architecture, iterative plans and frequent deliverables. This way, you will be in full control when it comes to timeline, quality and the ability to change things if/when needed.
_
Feel like sharing your own digitalisation experiences? Please get in touch!